

| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | ||||||
| 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| 16 | 17 | 18 | 19 | 20 | 21 | 22 |
| 23 | 24 | 25 | 26 | 27 | 28 | 29 |
| 30 | 31 |
- CM-EF-NEX
- 매크로렌즈 #리버스링
- 다이슨 #배터리
- Oh My Zsh #macOS
- egpu #aorus gaming box #gtx1070 #tb3
- Laptop #CPUID
- ESP32 #Arduino
- cycloidal #rv reducer
- razer #deathadder #viper #g102
- Tarantula #3D 프린터
- XTU #Virtual Machine System
- Arduino #Wall Plotter
- x99 itx/ac
- Linux #VirtualBox
- k6 #피코프레소
- macro lens #EF #FD
- 피코프레소 #ITOP40
- VMware #Shared Folder
- ITOP40
- TensorFlow #Python #pip
- VirtualBox #VMware
- Xeon #E5-2680
- Java #MacBook #macOS
- Octave #homebrew #macOS
- Dell #Latitude #BIOS
- Arduino #PlatformIO #macOS
- fat32 #rufus
- VNC #Firewall #CenOS7 #VMware
- centos7 #yum update #/boot
- Callaway #Mavrik #Epic Flash
- Today
- Total
얕고 넓게
[AI] Ollama + Dual GPU 본문
2025.02.10
3060 12GB x2 가 있으니 llama3.1:70b를 돌릴 수 있을까?
ollama run llama3.1:70b
Error: model requires more system memory (24.0 GiB) than is available (8.5 GiB)검색
GitHub - turboderp/exllama: A more memory-efficient rewrite of the HF transformers implementation of Llama for use with quantize
A more memory-efficient rewrite of the HF transformers implementation of Llama for use with quantized weights. - turboderp/exllama
github.com
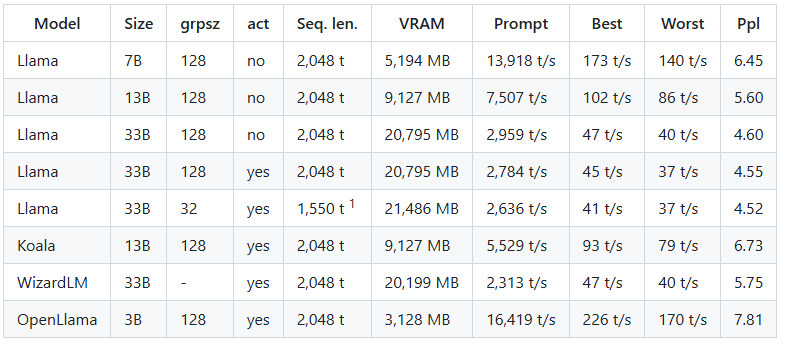
오리지날 모델이 아니지만 정리된 표
docker를 이용해 뭘 하라고 한다.
Ollama Llama Multi GPU Setup | Restackio
Ollama Llama Multi GPU Setup | Restackio
Learn how to efficiently configure Llama for multi-GPU setups using Ollama, enhancing performance and scalability. | Restackio
www.restack.io
Running Ollama with GPU Acceleration in Docker
For users who prefer Docker, Ollama can be configured to utilize GPU acceleration. Here’s how:
Install the Nvidia Container Toolkit: This toolkit is essential for enabling GPU support in Docker containers. You can find installation instructions on the Nvidia Container Toolkit GitHub page.
Pull the Ollama Docker Image: Use the following command to pull the latest Ollama image:
docker pull ollama/ollama
Run the Container with GPU Support: Start the container with the --gpus flag to allocate GPU resources:
docker run --gpus all ollama/ollama
어떤 글은 그냥 된다고 한다. P1000 + GTX1070에서도 비슷했던 것 같다.
시스템 메모리 증설 후 재확인 예정
Running Ollama on NVIDIA GPUs: A Comprehensive Guide
Running Ollama on NVIDIA GPUs: A Comprehensive Guide
Running Ollama on NVIDIA GPUs Are you curious about leveraging the POWER of NVIDIA GPUs to run Ollama? If you've dabbled in Large Language Models (LLMs), you might know that executing these models on a capable GPU can significantly enhance performance. In
www.arsturn.com
nivida-smi를 실행해본다.
된다!
PS C:\Users\garam> nvidia-smi
Mon Feb 10 00:47:16 2025
+-----------------------------------------------------------------------------------------+
| NVIDIA-SMI 560.94 Driver Version: 560.94 CUDA Version: 12.6 |
|-----------------------------------------+------------------------+----------------------+
| GPU Name Driver-Model | Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap | Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|=========================================+========================+======================|
| 0 NVIDIA GeForce RTX 3060 WDDM | 00000000:03:00.0 On | N/A |
| 30% 28C P8 12W / 170W | 492MiB / 12288MiB | 2% Default |
| | | N/A |
+-----------------------------------------+------------------------+----------------------+
| 1 NVIDIA GeForce RTX 3060 WDDM | 00000000:04:00.0 Off | N/A |
| 30% 26C P8 12W / 170W | 1MiB / 12288MiB | 0% Default |
| | | N/A |
+-----------------------------------------+------------------------+----------------------+
+-----------------------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=========================================================================================|
| 0 N/A N/A 2680 C+G ...siveControlPanel\SystemSettings.exe N/A |
| 0 N/A N/A 3748 C+G ...crosoft\Edge\Application\msedge.exe N/A |
| 0 N/A N/A 4500 C+G C:\Windows\explorer.exe N/A |
| 0 N/A N/A 7648 C+G ....Search_cw5n1h2txyewy\SearchApp.exe N/A |
| 0 N/A N/A 8748 C+G ...5n1h2txyewy\ShellExperienceHost.exe N/A |
| 0 N/A N/A 9320 C+G ...crosoft\Edge\Application\msedge.exe N/A |
| 0 N/A N/A 10444 C+G ...CBS_cw5n1h2txyewy\TextInputHost.exe N/A |
| 0 N/A N/A 10504 C+G ...Gig\CU\IntelWirelessDockManager.exe N/A |
| 0 N/A N/A 10948 C ...ta\Local\Programs\Ollama\ollama.exe N/A |
| 0 N/A N/A 11396 C+G ....Search_cw5n1h2txyewy\SearchApp.exe N/A |
| 0 N/A N/A 11824 C+G ...n\132.0.2957.140\msedgewebview2.exe N/A |
| 1 N/A N/A 10948 C ...ta\Local\Programs\Ollama\ollama.exe N/A |
+-----------------------------------------------------------------------------------------+
당근으로 메모리 8GBx4 구매 장착 -> 검은색에만 장착
32GB, 3060 12GB x2 상태에서
Ab 코드 뜨고 화면이 안나온다???
Ab는 CMOS에서 멈춰서 입력을 기다리는 것인데...
메모리 2개를 빼고 다시 -> 안나온다
메모리 1개만 남기고 -> 나온다
혹시나 싶어서 회색에 4개 장착 -> 안나온다 -> 코드 BB??
그래픽 카드 1개 빼고 -> 나온다
그래픽 카드 2개중 하나를 제일 바깥쪽에 -> 나온다 -> Window에서 카드 인식 안됨
...
마지막으로 1,2개 슬롯에 장착하고 2번에 케이블 연결 -> 화면 나오고, 윈도우에서 인식
한가지 이상한 것
CPUID에서 Link Width가 아까는 x8 이었는데 지금은 x16 이다.
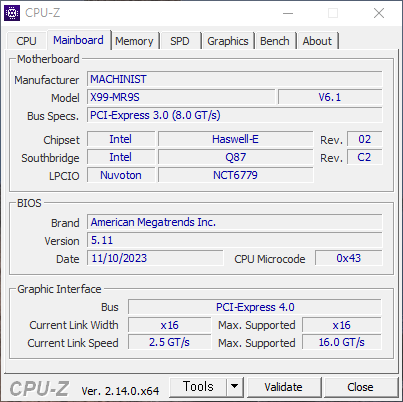
Link Speed 2.5GT/s가 맞는지 확인 필요
PS C:\Users\garam> ollama run llama3.1:70b

GPU0,1 모두 VRAM 9.4/12GB 사용
CPU는 45%, GPU 사용량이 0% ???
PS C:\Users\garam> ollama run llama3.1:8b

GPU를 안써서 CUDA 설치하려는데 VS를 깔아야 된다.
설치하고 CUDA install을 해도 중간에 에러
CUDA 설치와 확인 방법
*개인적으로 공부하기 위함과 업무상의 이유로 cuda를 설치해서 해야하는데 지난 6/9일에 시도할 때는여러...
blog.naver.com
그냥 nivida-smi를 해봤더니
PS C:\Users\garam> nvidia-smi
Mon Feb 10 21:55:50 2025
+-----------------------------------------------------------------------------------------+
| NVIDIA-SMI 572.16 Driver Version: 572.16 CUDA Version: 12.8 |
|-----------------------------------------+------------------------+----------------------+
| GPU Name Driver-Model | Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap | Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|=========================================+========================+======================|
| 0 NVIDIA GeForce RTX 3060 WDDM | 00000000:03:00.0 Off | N/A |
| 30% 29C P8 11W / 170W | 1MiB / 12288MiB | 0% Default |
| | | N/A |
+-----------------------------------------+------------------------+----------------------+
| 1 NVIDIA GeForce RTX 3060 WDDM | 00000000:04:00.0 On | N/A |
| 30% 29C P8 13W / 170W | 692MiB / 12288MiB | 5% Default |
| | | N/A |
+-----------------------------------------+------------------------+----------------------+
+-----------------------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=========================================================================================|
| 0 N/A N/A 6108 C ...al\Programs\Ollama\ollama.exe N/A |
| 1 N/A N/A 5144 C+G ...5n1h2txyewy\TextInputHost.exe N/A |
| 1 N/A N/A 5464 C+G C:\Windows\explorer.exe N/A |
| 1 N/A N/A 6108 C ...al\Programs\Ollama\ollama.exe N/A |
| 1 N/A N/A 6876 C+G ...h_cw5n1h2txyewy\SearchApp.exe N/A |
| 1 N/A N/A 12420 C+G ...ends\LeagueClientUxRender.exe N/A |
| 1 N/A N/A 13044 C+G ...crosoft\OneDrive\OneDrive.exe N/A |
+-----------------------------------------------------------------------------------------+중간에 드라이버 업데이트 해서 그런가 CUDA 버전도 올라갔다.
'IT > AI.ML' 카테고리의 다른 글
| [AI] Ollama + Vector DB (0) | 2025.02.28 |
|---|---|
| [AI] Ollama, Docker 등 자료 (0) | 2025.02.12 |
| [AI] 허깅페이스 자료 (0) | 2025.01.24 |
| [AI] NLP 용어 정리 (0) | 2025.01.24 |
| [AI] Llama 파인튜닝 재도전 (0) | 2025.01.23 |